アップルのAIがすごいところを技術的に見る。速度と正確性の両立がポイント
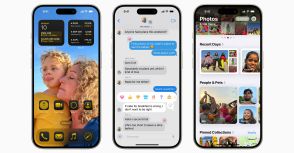
アップルは6月10日、独自のAI機能「Apple Intelligence」を発表した。製品はデバイスモデルとサーバーモデルの2つのAIモデルを使用しており、様々なタスクに役立つように設計されている。
モデルの開発には高品質なデータを使用し、事前トレーニングと事後トレーニングを行うことで、ユーザーの個人情報や操作履歴を使用せず、高品質なモデルを構築している。
アップルはプライバシー保護や責任あるAIの原則を重視し、ユーザーに力を与えるために様々なテストや評価を行っている。モデルのパフォーマンスは高く評価されており、特に敵対的プロンプトに対する耐性が強いとされている。

アップルが発表した独自のAI機能「Apple Intelligence」の技術的側面についての公式資料を読み解く。
アップルは6月10日(現地時間)、世界開発者会議(WWDC24)の基調講演において独自のAI機能「Apple Intelligence」を発表した。
同時にOpenAIとの提携も発表されたため一部混乱が見られたが、Apple Intelligenceには正真正銘、アップル謹製の基盤モデルが使われている。
ここではアップルが同日に公開した「Introducing Apple’s On-Device and Server Foundation Models」という技術資料を元に、アップル製AIモデルの技術的側面について見ていくことにする。
クラウドとオンデバイスで2種類のモデルを使用
Apple Intelligenceは、テキスト生成や添削、通知の管理、画像の作成、アプリの使用など、さまざまなタスクに役立つように特別に設計された2つのAIモデルを使用している。
1つはMacやiPhoneといったデバイス上で実行される約30億パラメーターの小型で効率的なモデル(以下デバイスモデル)。もう1つはより複雑なタスクのためにAppleのサーバー(Private Cloud Compute)上で実行されるより大型のモデル(以下サーバーモデル)だ。
なお、アップルはこの2つのモデル以外にもアプリ開発者向けのコーディングモデルや、画像生成モデルなど他のAIモデルも開発しており、近日中に詳細を共有する予定だという。
フィルタリングされた高品質なデータで事前&事後トレーニング
それではモデルの開発方法について見ていこう。
事前トレーニングにはアップルがオープンソースで公開している「AXLearn」という独自のフレームワークを使用している。
トレーニングデータは、ライセンス契約を結んだものおよび「AppleBot」が収集した公開データを使用しているが、サイト運営者はアップルが自社のコンテンツをAIのトレーニングに使用することを拒否できる仕組みも用意されている。
また、ユーザーの個人情報や操作履歴は一切使用せず、個人を特定できる情報はフィルタリングで除去されている。さらに、不適切な表現や低品質なコンテンツもフィルタリングされ、高品質な文書のみを使用してトレーニングされたという。
事後トレーニング用には、人間が作成したデータと人工的に生成したデータを組み合わせ、さらに厳密なデータ選別とフィルタリングをすることで、質の高いデータセットを構築。
さらに、「教師委員会」と呼ばれる複数のモデルを用いた「リジェクションサンプリング」および「人間のフィードバックを基にした強化学習(RLHF)」という手法により、 モデルは指示により忠実に従い、より高品質な結果を出力できるようになったという。
様々な最適化手法で高性能かつ高速化
Apple Intelligenceは高性能と高速化を両立するため様々な最適化処理が施されている。
大量のテキストデータ処理を効率化するためには「グループ化クエリによる注意機構(grouped-query-attention)」という技術が使われている。
さらに、単語を数値に変換する際に使用する「語彙埋め込みテーブル」を共有することで、必要なメモリと処理時間を削減している。
具体的にはデバイスモデルは4万9000語、サーバーモデルはそこにより多くの言語や専門用語を加えた10万語の語彙テーブルを持つ。
また、モデルのパラメータを少ないビット数で表現することで、メモリ使用量と処理速度を改善する「低ビット量子化」、モデルに追加学習させることで精度を維持しながらパラメータ数を削減する「LoRAアダプター」という技術も組み合わせて使用されている。
さらに、各操作に最適なビットレート(データ処理速度)を選択するための「Talaria」と呼ばれるツールや、「活性化関数」と「埋め込み」の量子化、そして「キーバリュー(KV)キャッシュ」の効率的な更新といった一連の最適化により、「iPhone 15 Pro」では、最初のトークンを生成するまでの待ち時間が約0.6ミリ秒に短縮され、毎秒30トークンの生成速度が達成されたという。
特筆すべきことに、このパフォーマンスはトークン推測手法(「token speculation techniques)を適用する前の水準であり、トークン推測によりさらに生成レートが向上するという。
モデルの適応は「アダプター」と呼ばれるモジュールを使用
「LoRAアダプター」についてもう少し詳しく見てみよう。
大規模言語モデル(LLM)は、膨大な数の「パラメータ」を持つことで、様々なタスクをこなせるが、すべてのタスクにすべてのパラメータが必要なわけではない。
Apple Intelligenceは「アダプター」と呼ばれる特定のタスクに特化したパラメータのセットのような小さなニューラルネットワークモジュールを使用する。
アダプターは、事前トレーニングされたモデルのさまざまな層に接続でき、タスクに応じてモデルの特定の部分(文章の理解に重要な「アテンション」や、情報を処理する「フィードフォワードネットワーク」など)を微調整する。
重要なのは、微調整はアダプター層に対してのみ適用され、元のモデルの主要な部分は変更されないということだ。これにより、モデル全体を再トレーニングするよりもはるかに高速かつ効率的にモデルを適応させることができるのだ。
また、必要なときにだけアダプターをロードすることでメモリを節約し、処理速度を向上させることもできる。Apple Intelligenceはそれぞれの機能に特化した幅広いアダプターを提供することで、カメレオンのように様々なタスクに柔軟に対応できるようになっている。
プライバシー保護を含めた「責任あるAI原則」掲げる
アップルはAIの開発において、「ユーザーに力を与え」「ユーザーを正しく表現する」「注意深く設計する」「プライバシーを保護する」という4つの「責任あるAI原則」を掲げている。
これらの原則は、ユーザーのニーズを満たすためのAIツールの開発、偏見や差別を避けるための努力、AIの悪用を防ぐための予防措置、そして強力なプライバシー保護機能の実装などに反映されている。
アップルは、ユーザーのプライバシーを保護するために、デバイス上で処理をすることや、ユーザーの個人情報を使わずにモデルをトレーニングすることなどを実施している。また、性能を評価する際には有用性だけでなく意図しない危害についても考慮している。
パフォーマンスと評価:プロンプトインジェクションへの耐性が強く、プロンプトへの追従性も高い
アップルは特定の機能に対するアダプターとベースモデルの両方に対してパフォーマンス評価を公開している。
実際の使用環境を反映した多様な文書タイプと長さを含む750の応答データセットを使用した要約機能の評価で、アダプターを搭載したモデルは同等のモデルよりも優れた要約を生成するという結果になった。
下記は「Human Evaluation」と呼ばれる「ブレインストーミング」「分類」「質問応答」「コーディング」などさまざまな難易度やカテゴリーを含む多様なプロンプトを用いて、アップルのモデルと競合モデルのどちらの回答がが好まれるかを比較したものだ。
比較対象は、誰でも利用できるオープンソースモデル(Phi-3、Gemma、Mistral、DBRX)と、有料の商用モデル(GPT-3.5-Turbo、GPT-4-Turbo)。
結果として、アップルのモデルは他の多くのモデルよりも好まれ、約3Bパラメーターしかないデバイスモデルでも「Phi-3-mini」「Mistral-7B」「Gemma-7B」といった大型モデルよりも好まれるという結果を示した。
また、サーバーモデルは「GPT-4-Turbo」には及ばないものの「DBRX-Instruct」「Mixtral-8x22B」「GPT-3.5-Turbo」よりも好まれる結果を示した。
下記は「敵対的プロンプト」と呼ばれる、モデルをだまして有害なコンテンツを生成させようとするさまざまなトリッキーな質問をモデルに投げ、人間が「違反率(モデルが問題のある回答を生成する割合)」を測定したもの。
テストの結果、両モデルともオープンソースや市販のモデルと比較して、違反率が低く、より堅牢であることがわかった。
さらにアップルは、内部および外部の専門家チームと協力し、手動および自動の両方で「レッドチーム演習」(システムの脆弱性を攻撃によって見つけるテスト)を実施し、モデルの安全性をさらに評価している。
モデルが指示にどれだけ正確に従えるかを評価する「Instruction-Following Eval (IFEval)」でも、両モデルが競合モデルと比較して、複雑な指示によりよく従うことが明らかになっている。
要約や作文など文章作成における様々な側面をカバーするベンチマークでも競合モデルと同等もしくはそれ以上の結果を示している。これは作文に特化といったアダプターは使用しておらず、基盤モデルだけの成績だ。
ベンチマーク結果の中で目立つのは、敵対的プロンプトに対する耐性だ。ほぼすべての競合モデルが10%以上の確率(GPT-4-Turboは20%超え)で敵対的プロンプトに引っかかって有害な出力をするのに対し、Apple Inteligenceはデバイス、サーバー両モデルとも一桁台という低い違反率を示している。
また、プロンプトへの追従性を評価する「IFEval」の値も高く、特にデバイスモデルは競合モデルより1ランク上の追従性を持つと思われる。
2つの基盤モデルを併用しつつ、軽量なモジュールを使い、正確性とスピードを両立
以上、Apple Intelligenceの構成、開発手法、セキュリティー、ベンチマークなどについて見てきた。
すべての仕事をクラウド上の「基盤モデル」に任せるChatGPTのような仕組みを取らず、サーバー上のLLMとデバイス内のSLMという2つの基盤モデルを併用しつつ「アダプター」と呼ばれる軽量なモジュールに追加学習を任せることにより、正確性とスピードの両方を実現しているということのようだ。
すべてのアップルユーザーが利用できるようになるにはまだしばらく時間が必要だろうが、AI技術に対するアップルの方向性が具体的に示されており、大きな進歩だと感じた。
文● 田口和裕