“革命”起こした画像生成AIに暗雲 「Stable Diffusion 3 Medium」の厳しい船出
Stability AIが最新画像生成AI「Stable Diffusion 3 Medium(SD3M)」を公開したが、品質に課題があり普及が進まない状況が続いている。
SD3Mは複雑なプロンプトにも対応し、テキストの理解が強化されているが、性能面で課題が浮き彫りになっている。
Stability AIは有料サービスに移行したい意向があるものの、SD3Mの性能には問題があり、乗り越えるのが困難な状況が続いている。

Stability AIの最新画像生成AI「Stable Diffusion 3 Medium(SD3M)」が公開されました。しかし、意図的に落とされた品質に大きな課題が発見されており、普及が進むのか見えない状況になっています。
6月12日、Stability AIの画像生成AI「Stable Diffusion 3 Medium(SD3M)」が公開されました。Stability AIは安定的な収益につながるビジネスモデルの構築に課題を抱えており、最新シリーズ「Stable Diffusion 3(SD3)」をどう位置づけるかが生命線と思われます。そこで、有料APIの使用が必須という形で性能の高い「Stable Diffusion 3 Large(SD3L)」を先行リリースしていました。SD3を「オープン化する」とX上で発言していた創業者のEmad Mostaque氏が4月にCEOを退任したことで約束は守られるのかとも危惧されてきました。結果としてStability AIは、品質を落としたSD3Mを出すという判断をしてきました。しかし、SD3Mはライティングに高い表現力を持つ一方、意図的に落とされた品質に大きな課題が発見されており、普及が進むのか見えない状況になっています。
文章のように複雑なプロンプトも的確に理解
Stability AIはSD3Mを「生成AIの進化における大きなマイルストーン」と位置づけ、「強力なテクノロジーを民主化するという当社の取り組みを継続するもの」としています。ライセンスとしては、非商用向けの無料ライセンスと、売上が100万ドル以下などの条件が付いた月20ドルのクリエイターライセンス(商用ライセンス)が用意されています。それ以上の収益を得る企業の場合は別途ライセンス契約を結ぶ必要があり、その料金は明らかにされていません。
そもそも、Stable Diffusion 3の画像生成の方法はこれまでとアーキテクチャーが大きく異なっています。過去のStable Diffusionモデルでは、画像処理に特化した拡散アーキテクチャー「U-Net」が使われていました。それがSD3では自然言語処理で成功を収めたTransformerベースのモデルに移行し、「Multimodal Diffusion Transformer (MMDiT)」と「Rectified Flow」という新しい仕組みを採用しています。
MMDiTは、テキストと画像とを同時に扱うことが得意で、より複雑な文章のプロンプトを書いても、それを適切に読み解き、画像化する能力が高い技術とされています。Rectified Flowは、ノイズ除去プロセスを改善した手法で、これまでよりも高品質な画像が出力可能です。SD3はこれにより、長文のテキストプロンプトを入力しても、それに合わせた適切な画像を生み出せることを強みとしてアピールしています。
SD3がこうしたアーキテクチャーを採用したのは、複数の種類のデータ(モダリティー)を組み合わせて理解・処理できるマルチモーダルAIを目指して開発されたためです。画像だけしか扱えないAIから文字などの複数のデータを理解・処理できるようにすることで、今後応用範囲を広げていくことが目指されています。
実際に、テキストの理解は非常に強化されています。
公式にサポートされている実行環境のアプリ「ComfyUI」向けにサンプルとして公開されたWorkflowを見ると、テキストによりプロンプトを入力すると、テキストを画像化するうえで処理をする3つの「クリップ(CLIP)」で分析する仕組みになっています。特にSD3を特徴づける「T5 XXL」というクリップを使うことで、複雑な文章を入れてもしっかりプロンプトに追従してくれるようになっています。これまでのStable Diffusionでは通常、クリップは1つでした。プロンプトも「a girl, black hair」などの単語を並べていくことが中心でしたが、SD3ではかなり複雑な文章で指示しても、文脈を踏まえて画像を生成してくれるようになったのです。
ただ、このCLIPのサイズが半端なく大きくて、圧縮率の低いものが10GB、もしくは15GBもあり、もっとも圧縮した基本のものでもファイルで5GBあります。SD3Mで小さなクリップを使用するように設定するだけでVRAMが12GBくらい必要となります。なので、そのために、SD3Mを動かすための要求されるPCスペック水準は高いですね。SD3Mの画像の学習済みデータの本体ファイルが4.34GBなので、公開されたCLIPファイルのほうが大きいくらいです。
なお、SD3Lは80億パラメーターを持つとされていますが、Mediumは20億パラメーター。ファイルサイズはSDXLの6.94GBよりも小さいサイズになっています。
ライティングと発色は美しい。リアル系の画像は写真レベル
実際に出力はどうか。
サンプルとして公開されているワークフローで生成してみるとかなりきれいに出ました。SD3Mでは自然なライティングができていたりと、SDXLより優れていると感じられる部分はあります。SDXLで同じような発色を出そうと思うと、ファインチューニング(微調整)したカスタムモデルや、LoRAを組み合わせなければ難しいのではないかと思います。ただ、劇的に変化したかというと、そこまでは達していないように感じます。
サンプルのワークフローでは、画像は1024×1024というSDXLと同様の解像度で出力されます。ディティールを書き出してもくれるので少し物足りなくも感じますが、画像はディティールや画質を維持したまま画像サイズを拡大できるアップスケーラーを使うのが前提になっているようです。こちらもサンプルのワークフローが用意されています。
テストのため、自然文での長文プロンプトを簡単に生成するのにいい方法がないかと考えたのですが、ChatGPTに自分のプロフィール写真を解析させる方法を取りました。日本人の中年男性を描写するプロンプトが生成されました。それでSD3Mで生成してみたところ、どこかにいそうな妙な実在感のある中年男性が出てきました(笑)。プロフィール写真としてはそのまま使えそうなリアルさで、一見写真と見間違えてしまいそうです。写真っぽい印象は非常に自然で、単純な生成だけで、ここまで出せるというのはすごいとは思います。
複雑な場面もテキストだけで生成可能。ただし気になる部分も
次に、サンプルワークフローで公開されている「マルチCLIP」という機能を使い、複雑なプロンプトを試してみます。
これは3種類のプロンプトを同時に入力し、それぞれのプロンプトを公平に反映させるという、MMDiTの強さを生かした仕組みです。これまではタグごとに分けた形で入力するのが基本で、プロンプトの影響力は前に書かれている単語ほど影響力が大きいものでした。一方、SD3Mでは、3種類の分割したプロンプトに同じ重みで生成ができるようになっています。
試しに「アンドロイドがいる研究室」という条件で、やはり同じようにChatGPTでプロンプトを作成してみました。
その複雑なプロンプトを3つに分割して、CLIPの1つ目に「アンドロイド」、2つ目に「研究室」、3つ目に「背景」の詳細をそれぞれ入れて生成してみました。生成された画像を見てみると、細かいところの破綻はありますが、研究室のホワイトボードに数式やグラフらしきものが書いてあったり、ディテールがちゃんと出ています。さらに、プロンプトの要素の一部だけを修正して構成要素を変えたりできるようにもなっています。
これがSD3ならではの特徴です。複雑なプロンプトにより、複雑な場面を生み出せるわけです。
ただし、気になる部分もありました。女性アンドロイドを指定して何度か生成してみたのですが、なんとなくプロンプトが無視されている気がします。プロンプトが長すぎるのかもしれません。ただ、DALL·E 3(ChatGPT)で画像を同じプロンプトで生成した場合には、きちんと女性アンドロイドが出ています。プロンプトをシンプルにするとSD3Mでも出力できたので、効果が大きいテキストの量は存在しそうです。
アニメ系は基本的にはそれなりにきれいな描画が出るものの、指や髪の破綻が激しいですね。この辺りはSDXLの基本的な特徴を引き継いでいるような印象も受けます。
参考までに、昨年の記事で作成した画像を同じようにChatGPTに解析させて、同じように長文プロンプトを作成し、それらにどれぐらい近い画像を生成できるのかを、様々なサービスで比較してみました。SD3M、DALL·E 3(ChatGPT)、Midjouney、Nijijounery、NovelAIの各種です。ポイントは色の違いで、赤、青、緑・黄というキャラクターの服装の違いを描画できるかというところですが、SD3Mでもそれなりにできてはいるようです。ただ、やや棒立ちに近く、そのままでは魅力的な画像とは言えませんでした。とはいえ、今後ファインチューニングがされれば、かなり改善してくる可能性が感じられます。
「芝生の上で横になっている」指示ができない? 品質に暗雲
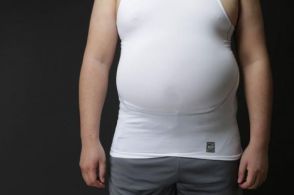
一方で、リリースから1日目で、RedditでSD3Mについての奇妙な報告が相次ぎました。「芝生の上に横になっている」という単純な指示の画像が、まともに生成できないというのです。
SD3Mを触りはじめて確かに違和感はありました。SDXLよりも破綻した人体が生成されることが多い印象がしたのです。検証もしてみましたが、実写風の画像にしても、腕が消えていたり、指がくっついていたり、足が複数生えていたりと、体が破綻している画像がよく出ました。人物の顔やライティングはクオリティーが高いのですが、人物の生成に問題があるというのは間違いないようです。
やはり同じ条件で生成してみようということで、少しだけ工夫して「芝生の上に座っている女性」としてみました。脚と手が交差する構図は、オブジェクト同士の干渉があるために、生成AIは苦手とするものであるので、より顕著に特徴が出ると考えました。SD3M、DALL·E 3(ChatGPT)、Midjouney、Nijijounery、Novel AIで行った結果、SD3Mは不自然に身体が破綻する頻度が高い印象がします。
最後に、APIを使って、有料のSD3Lを試してみました。公式サイトを利用しています。完全ではないのですが、破綻する割合は低いことが確認できました。
つまり、SD3Mはオープン化して公開するために、機能を制限して公開したと考えられます。もちろんポルノ画像などを生成しにくいようにしているのだろうとは推測できます。しかしそれ以上に、SD3Mを極端にデータサイズが小さくしたことで大きな副作用があらわれているのではないでしょうか。
この実情がわかってくると、ユーザーの間ではSD3Mに対する失望が広がりました。SD3Mのそのままでは性能には限界があることがはっきりしてきました。ユーザーがファインチューニングしたモデルやLoRAを開発することなしに、SDM3の性能を引き上げることは難しいと考えられます。SDXLはリリースから10ヵ月で、コミュニティーの成長もあり、高性能なチェックポイントやControlNet(制御ツール)など、豊富な環境が整いはじめてきています。急いでSDXLからSDM3に移行すべき理由がユーザーには見えないのです。
有料サービスに移行させるには性能が課題に
過去、Stability AIはSDやSDXLを無料で自由に扱えるライセンスで公開したことで、画像生成AIの普及や後発企業を生み出しました。しかし、その普及によって生まれた利益を大きく得られてはいません。虎の子のSD3を通じて有料ユーザーへと移行させていきたいという本音があることは感じられます。しかし、無料状態に慣れたユーザーを、商用利用のための月20ドルの有料サービスへと誘導するハードルには非常に高いものがあります。しかも、肝心のSD3Mの性能には課題が見えています。
SD3Mはかなり厳しい船出となったと言えるでしょう。果たしてStability AIは、この状況を乗り越えられるのでしょうか。
筆者紹介:新清士(しんきよし)
1970年生まれ。株式会社AI Frog Interactive代表。デジタルハリウッド大学大学院教授。慶應義塾大学商学部及び環境情報学部卒。ゲームジャーナリストとして活躍後、VRマルチプレイ剣戟アクションゲーム「ソード・オブ・ガルガンチュア」の開発を主導。現在は、新作のインディゲームの開発をしている。著書に『メタバースビジネス覇権戦争』(NHK出版新書)がある。
文● 新清士 編集●ASCII