# Fugaku-LLM

「Llama 3.1」ベースの日本語追加学習LLM、サイバーエージェントが爆速公開
(株)サイバーエージェントは7月26日、米Metaが開発したオープンLLM「Llama 3.1 70B」をベースに、日本語データで追加学習を行なったLLM「Llama-3.1-70B-Japanese-Instruct-2407」を公開した。同モデルは「Hugging Face」にて公開され

JPモルガン、対話型AIを社内展開 調査アナリストに活用=FT
[26日 ロイター] - 米金融大手JPモルガン・チェースは、対話型AI(人工知能)の社内展開を開始し、米オープンAIの「チャットGPT」の自社版が調査アナリストの業務をこなせると従業員に伝えている。英紙フィナンシャル・タイムズ(FT)が26日報じた。FTが社内メモを基に
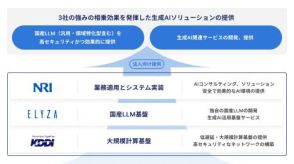
野村総合研究所、ELYZA、KDDIの3社、法人向け生成AI提供で協業
株式会社野村総合研究所(以下、NRI)、株式会社ELYZA、KDDI株式会社の3社は24日、法人顧客向けの生成AIソリューション提供に向けて協業すると発表した。3社は協業により、法人顧客の機密事項や業務特化事項を含む情報を扱える高セキュリティかつ効果的な生成AIソリューションを、順次提供開始
ソフトバンク、生成AIサービスの回答精度向上を支援するRAGデータ作成ツールを提供
ソフトバンク株式会社は22日、AIの教師データを作成するアノテーションサービス「TASUKI Annotation」で、生成AIサービスの回答精度の向上を支援するRAGデータ作成ツールを提供開始した。 生成AIサービスの開発や導入を自社で行う企業は、同ツールを活用することで、デ

富士通とCohere、日本語LLM「Takane」共同開発で戦略的提携
富士通とCohereは、企業の成長や社会課題の解決を支援する生成AIの提供を目指し、企業ニーズを満たす大規模言語モデル(LLM)の開発とサービス提供に向けた戦略的パートナーシップを締結した。共同開発したLLMは富士通がグローバル市場向けに独占的に提供する。富士通はCohereへの出資も行なう。

富士通、AI新興CohereとLLM共同開発 日本語に長けたモデル「Takane」(高嶺)
富士通は7月16日、カナダのAIスタートアップCohereと大規模言語モデル(LLM)を共同開発すると発表した。同社に出資の上パートナーシップを締結。CohereのLLM「Command R+」を基に、日本語に長けたモデル「Takane」(高嶺、仮称)を共同開発する。Takaneは9月をめど

富士通、企業向け生成AIでCohereと戦略的提携--日本語LLM「Takane」を共同開発
富士通は7月16日、企業向けAIを提供するCohereと戦略的パートナーシップを締結したことを発表した。両社は今後、Cohereの大規模言語モデル(LLM)をベースとした日本語強化版となる「Takane」(仮称、高嶺:タカネ)を共同開発する。 Takaneは、2024年9月から

【完全解説】NECの生成AI戦略、独自の生成AI「cotomi」はGPT-4らとどう差別化する?
近年、生成AIの産業・ビジネス用途の活用が急速に広がる中で、大規模言語モデル(LLM)の開発競争も激化している。その対立軸としては、(1)汎用型LLM vs 個別型LLM、(2)汎用言語型LLM(英語) vs 特定言語型LLM、(3)クローズドソース vs オープンソースなどがある。今回は、
デジタル庁お墨付き! 即戦力のプロンプト集で「ChatGPT」をフル活用
“やじうまの杜”では、ニュース・レビューにこだわらない幅広い話題をお伝えします。 「ChatGPT」をはじめ、「Claude」、「Gemini」といった大規模言語モデル(LLM)が注目を集めています。これらのLLMは、私たちの日常生活やビジネスシーンに徐々に浸透しつつあるのはご

商用可能な日本語LLM「CyberAgentLM3」が一般公開、性能は「Llama-3-70B」と同等
(株)サイバーエージェントは7月9日、225億パラメーターの日本語LLM(大規模言語モデル)「CyberAgentLM3」を一般公開した。同モデルは商用利用可能な「Apache License 2.0」で提供されており、「Hugging Face」よりダウンロード可能。Hugging Fac

サイバーエージェント、225億パラメータの日本語LLMバージョン3を公開--スクラッチ開発
サイバーエージェントは7月9日、225億パラメータの日本語LLM(大規模言語モデル)である「CyberAgentLM3」を公開したことを発表した。 同社はかねてから日本語LLMの開発に取り組み、2023年5月に独自の日本語LLMである「CyberAgentLM」を一般公開。同年

GPT-4超え性能を実現した国内スタートアップELYZA、投資額の多寡ではなくチャレンジする姿勢こそ大事
ELYZA(イライザ)が、700億パラメータの「Llama-3-ELYZA-JP-70B」と、80億パラメータの「Llama-3-ELYZA-JP-8B」を開発した。日本語に特化した同社の国産LLM(大規模言語モデル)である「ELYZA LLM for JP」の最新モデルと位置づけている。

FIXERの「GaiXer」、Claude 3.5 Sonnet/Gemini 1.5 Pro/Gemini 1.5 Flashが利用可能に
FIXERは、エンタープライズ向け生成AIプラットフォーム「GaiXer」において、新たにAnthropicの「Claude 3.5 Sonnet」、Googleの「Gemini 1.5 Pro」および「Gemini 1.5 Flash」の3つのLLMが利用可能になったことを発表した。

「電力を制約すべきでない」 “国産”生成AIの開発活発化 KDDIやソフトバンクなど 利用拡大で電力需要も増加、対策急務に
生成AIを動かす基盤となる大規模言語モデル(LLM)をめぐる国内企業の動きが活発化している。今月にはKDDIやソフトバンク、パナソニックが矢継ぎ早に新たな取り組みを発表。一方で、懸念されるのが電力需要の爆発的な増加だ。2040年のトラフィック(情報量)は20年から最大で348倍に達するとの予

自分の書いた文章をAIに学習させたくないけどAIを使いたいなら、ブラウザ「Opera」がおすすめ!
「生成AIを使ってみたいけど入力した情報を学習されるのは嫌」という場合もあるでしょう。特にクリエイティブなお仕事をされている方の場合、AIによるアドバイスやアイデアは得たいけれど、自分の入力を学習されてしまうのは絶対で困る!という場合があるはず。この場合、クラウドベースのAIでは

国内最大1000億パラメーター規模…パナソニックHDが自社専用の生成AI基板開発へ
パナソニックホールディングス(HD)は2日、人工知能(AI)開発のストックマーク(東京都港区)と共同で、国内最大規模の自社専用大規模言語モデル(LLM)の開発を始めたと発表した。ストックマークのLLMは、AIが事実に反する回答を述べる現象を抑制できる特徴を持つ。パナソニックHDはこのLLMに自

韓国・AIオーダーメードの技術適用のゲーム…「実際の人とチャット」感覚で没入感
【07月03日 KOREA WAVE】「ゲームが面白いかどうかを検証するために、論文水準以上のディープラーニング(深層学習)技術が先行した」韓国のクリエイティブスタジオ「レルゲームズ(ReLU Games)」のシン・スンヨンCTO(最高技術責任者・開発室長)はAI(人工知能)推理

日本語特化の生成AI、国内企業の開発加速…「チャットGPT」など米国製の精度低く
日本語に特化した生成AI(人工知能)の基盤技術「大規模言語モデル(LLM)」を開発する動きが広がっている。現在、広く普及している米国製生成AIに使われているLLMは、日本語の学習量が極めて少なく、回答や文書作成の精度が低く使い勝手が悪いためだ。和製LLMが普及すれば、AIの活用がさらに広がる
パナソニックHD、自社のAI基盤を開発
パナソニックホールディングス(HD) <6752> は2日、生成AI(人工知能)の基盤となる大規模言語モデル(LLM)をグループ専用に開発すると発表した。AIスタートアップ企業のストックマーク(東京)と協業する。数値が大きいほどさまざまな指示に対応できる「パラメーター」数が1000億で、企業

パナHD、大規模言語モデル構築 社内専用、秋に利用開始 設計や製造現場で活用
パナソニックホールディングス(HD)は2日、社内専用の大規模言語モデル(LLM)を人工知能(AI)開発のストックマーク(東京)と協業し、構築すると発表した。ストックマークが開発したLLMに社内データを追加学習させることで、グループ内の業務に特化したLLMを構築。秋ごろの運用開始を目指している。