日本語特化の生成AI、国内企業の開発加速…「チャットGPT」など米国製の精度低く
日本語に特化した生成AIの基盤技術「大規模言語モデル(LLM)」の開発が広がっている。日本語学習量の不足により、現行の米国製生成AIの精度や使い勝手が低いためだ。
日本企業がAI活用に注力し、パナソニックHDがストックマークと提携し、日本語特化型LLMの開発を進めている。業務効率化のためAI導入が進み、NTTや他通信大手も日本語処理性能に重点を置いたLLMを提供している。
米国製生成AIの課題も浮上し、業務で使用するには不十分な学習量や専門知識に関する不足が指摘されている。一般向けの生成AIはハルシネーション(幻覚)が高頻度で起きるなど、課題が多い。
日本語に特化した生成AI(人工知能)の基盤技術「大規模言語モデル(LLM)」を開発する動きが広がっている。現在、広く普及している米国製生成AIに使われているLLMは、日本語の学習量が極めて少なく、回答や文書作成の精度が低く使い勝手が悪いためだ。和製LLMが普及すれば、AIの活用がさらに広がる可能性がある。(杉山正樹、高市由希帆)
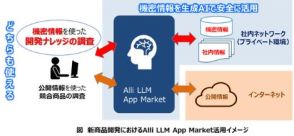
パナソニックホールディングス(HD)は2日、AI開発を手がける新興企業ストックマーク(東京)と連携し、日本語特化型LLMを開発すると発表した。新製品設計や顧客への回答作成支援といった社内業務での活用を想定しており、今秋までの構築を目指す。
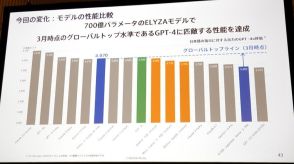
性能の指標となるモデルサイズ(パラメーター)は1000億と、自社業務用LLMとしては国内最大規模になる見込みだ。
日本語やビジネス関連の情報を中心に学習させたストックマークのLLMに、製品やサービス、技術といったパナソニックグループの社内情報を追加で学習させる。
NTTも今年3月に世界トップ級の日本語処理性能を備えた「tsuzumi(ツヅミ)」の提供を始めた。ソフトバンクやKDDIも日本語特化型LLMの開発を進めている。
開発が相次ぐ背景には、近年、業務効率化のため生成AIを活用する日本企業が増えてきたことがある。
パナソニックHDのシステム子会社が昨年6月~今年5月に、国内の社員の業務時間を計18万6000時間削減するなど成果を出している企業もある。その反面、多くの企業が採用する米新興企業オープンAIの「チャットGPT」など米国製生成AIの課題が浮上してきた。
例えば、チャットGPTのLLM「GPT―4」の場合、学習量全体に占める日本語の割合は0・1%程度とされるなど、学習量が少ない。このため、「業務で使用するには不十分」との声も多い。
一般向けの生成AIは、各企業が保有する専門知識に関する学習も足りていないため、実在しない事柄を事実のように回答する「ハルシネーション(幻覚)」も高頻度で起きるという。