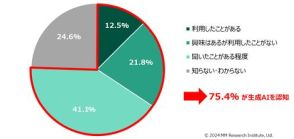
ChatGPTでも不合格? 会話型AIの「本当の実力」を測る新ベンチマークが登場
会話型AIが急速に増えており、Sierraが新しいベンチマーク「t-bench」を発表した。
既存の評価ベンチマークが不十分だとし、より複雑な会話やタスクを評価する必要性を主張。
Sierraの新しいベンチマークは連続した会話や尺度に対応し、AIエージェントの性能を客観的に評価する取り組み。

ChatGPT、Claude、Gemini、Mistralなど、会話型AIが次々と登場している。ほんの1年前まではChatGPTほぼ一択であったが、いまは多すぎてどれを選べばいいかわからない人も多いはずだ。
そんな中、AIスタートアップのSierraが、会話型AIの精度を“客観的に”測るベンチマーク「t-bench(タウベンチ)」を発表した。
SierraはOpenAIの取締役会のメンバーであるブレット・テイラー氏と、GoogleでAR/VR事業に従事していたクレイ・ベイバー氏が創業したAIスタートアップだ。
同社は2024年6月、会話型AIエージェント(以下、AIエージェント)のパフォーマンスを評価する新しいベンチマーク「t-bench(タウベンチ)」を発表。t-benchはLLMベースのユーザーシミュレーターを使って、AIエージェントが複雑な会話やタスクを遂行できているかをテストし、その性能を客観的に評価するという。
これまでもWebArena、SWE-bench、Agentbenchなど、既存の評価ベンチマークはいくつか存在した。だがSierraの研究責任者カルティク・ナラシムハン氏は、「従来のベンチマークはいくつかの重要な分野における測定が不足していた」と主張する。
ユーザーがAIエージェントとする会話は「一問一答」ではなく、より複雑で連続したものであるはずだ。だが既存のベンチマークは、たとえば「今日の天気はどうですか?」「最高気温は24度、最低気温は16度で晴れています」というような、「1ラウンド」ですべての情報を交換する会話のみを評価対象としている。
ナラシムハン氏は「これだけでうまく動いているかを評価するのは現実的でない」と言う。また、連続した会話であっても、会話全体の「平均的なパフォーマンス」評価にとどまり、信頼性や適応性といった尺度には対応していない。