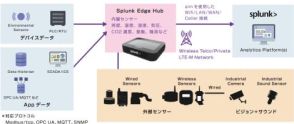
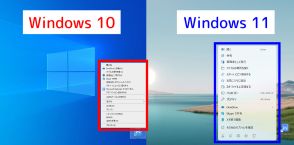
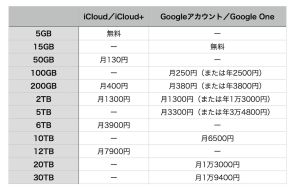
リコー、指示追従性能や要約性能を向上した130億パラメーターの日本語LLMを開発
株式会社リコーは、国立研究開発法人理化学研究所 革新知能統合研究センターと共同で、日本語LLMの指示追従性能向上を実現した。
リコーが独自開発したインストラクションデータも追加学習させ、要約タスクで優位性を確認。
LLMの性能向上にはデータ品質の重要性が示唆され、AIによる要約生成がリコーの強化領域として注力。
株式会社リコーは3日、国立研究開発法人理化学研究所 革新知能統合研究センター 言語情報アクセス技術チーム(以下、理研 AIP)との共同開発で得られたインストラクションデータを、リコー製130億パラメーターの日本語LLMに追加学習させ、LLMの指示追従性能(ユーザーの指示や質問に対して自然な回答ができる能力)が向上するという結果を得たと発表した。また、リコー独自開発のインストラクションデータを追加学習させた結果においても、指示追従性能の向上を確認し、要約タスクでの優位性を確認したという。
リコーは今回、インストラクションデータ「ichikara-instruction」(1万329件)を用いて、リコー製LLMにインストラクションチューニングを行った。結果、複雑な指示・タスクを含む代表的なベンチマーク「ELYZA-tasks-100」において、チューニング前と比較して、指示追従性能の大幅なスコア向上を確認した。また、リコーが独自開発した3556件のインストラクションデータを用いたチューニング結果でも、同ベンチマークにおいて、同様にスコアが大きく向上した。
これらの結果から、「ichikara-instruction」はインストラクションデータとして高品質なデータセットであること、また、リコー製インストラクションデータにおいても高スコアが得られたことから、LLMの性能向上にはデータ量だけでなく、データの品質が重要だということが示唆されたとしている。
また、要約タスクを独自評価したところ、特に長文要約においては、リコー製データセットの優位性が確認できたという。
AIによる要約生成は顧客のニーズが高く、リコーが強化していく領域だと説明。リコーは継続的にデータ開発を進めており、2024年5月末時点では5000件超のインストラクションデータの開発を完了しており、今後、これらをリコーが提供するさまざまなAIソリューションに活用することで、より高品質なサービスの提供を目指すとしている。